About
I’m a second-year Ph.D. student in Computer Science at the University of Texas at Austin, with a primary focus on Multimodal Large Language Models, Speech and Audio Understanding, and Text-to-Speech.
Previously, I served as a research intern at Microsoft Research Asia, under the mentorship of Lei He and Xu Tan, concentrating on Multilingual Text-to-Speech.
During the summer of 2023, I had the opportunity to work as a research intern at the SALT Lab at UT-Austin, collaborating with Prof. David Harwath and Prof. Eunsol Choi. Additionally, I’ve been a research Intern at the X-Lance Lab at SJTU since 2021, supervised by Prof. Xie Chen.
Download my resumé.
- Multimodal Large Language Model
- Self-Supervised Learning
- Speech and Audio Understanding
-
Ph.D. in Computer Science, 2024 - 2028 (expected)
The University of Texas at Austin
-
BSc in Electrical Engineering & Zhiyuan Honors Program of Engineering, 2020 - 2024
Shanghai Jiao Tong University
News
- 2025.08 2 paper was accepted by EMNLP 2025.
- 2024.05
 BAT was accepted by ICML 2024.
BAT was accepted by ICML 2024.
- 2024.04 EAT: Self-Supervised Pre-Training with Efficient Audio Transformer was accepted by IJCAI 2024.
- 2023.12 We release emotion2vec, the first universal speech emotion model that excels across diverse emotional tasks, languages.
- 2023.12 1 paper was accepted by ICASSP 2024. See details.
- 2023.09 🚀 We release Fast-HuBERT, accelerating HuBERT pre-training in 5.2X speedup without performance drop.
- 2023.09 2 papers were accepted by IEEE ASRU 2023. See Fast-HuBERT and paper b.
- 2023.08 Our work MT4SSL was nominated in ISCA Interspeech Best Student Paper Shortlist.
- 2023.07 I've started working as a visiting scholar at UT-Austin! 🤘
- 2023.05 3 papers were accepted by ISCA INTERSPEECH 2023. See paper a, paper b, and paper c.
- 2023.02 1 paper was accepted by ICASSP 2023. See details.
Featured Publications
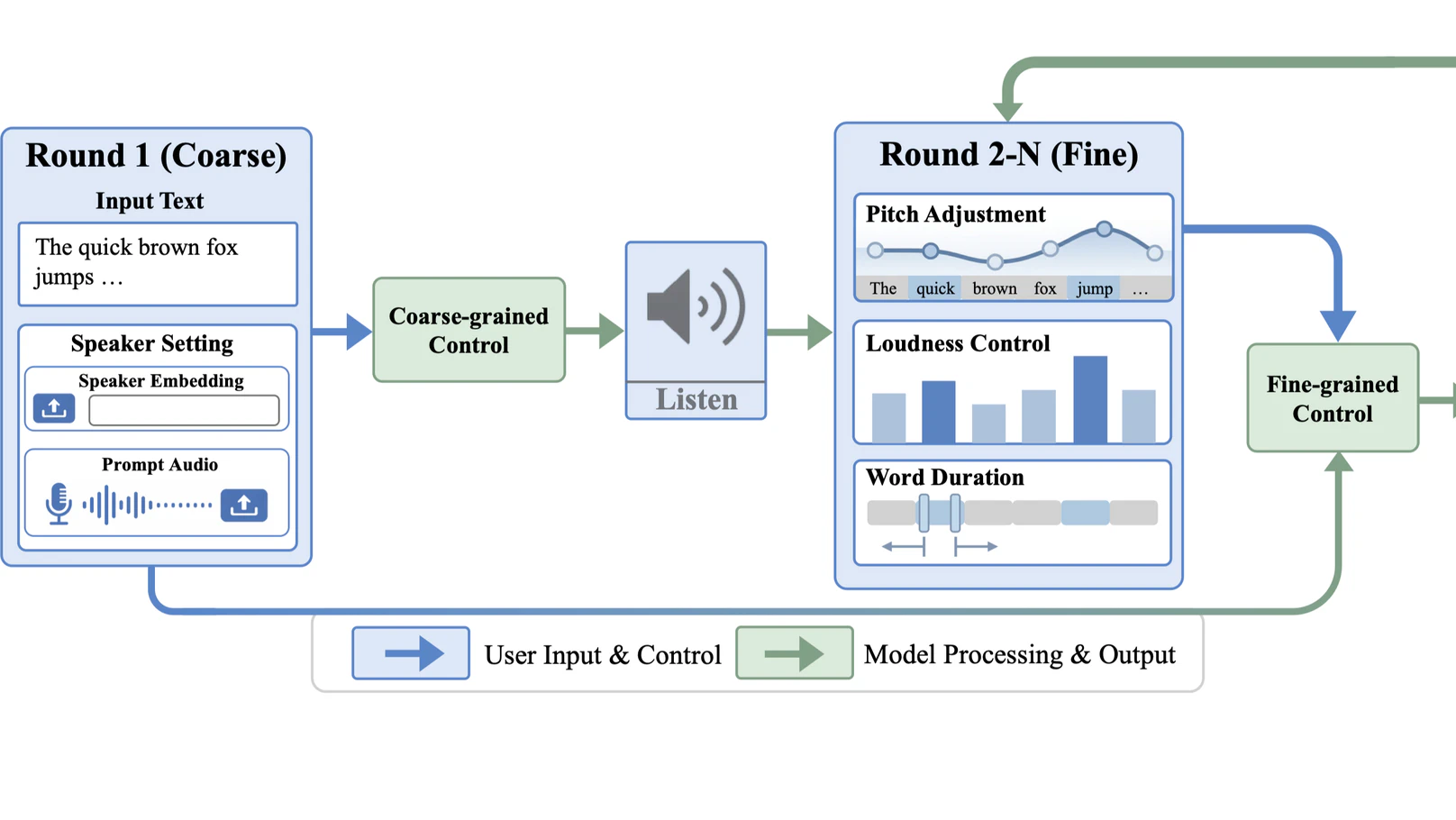
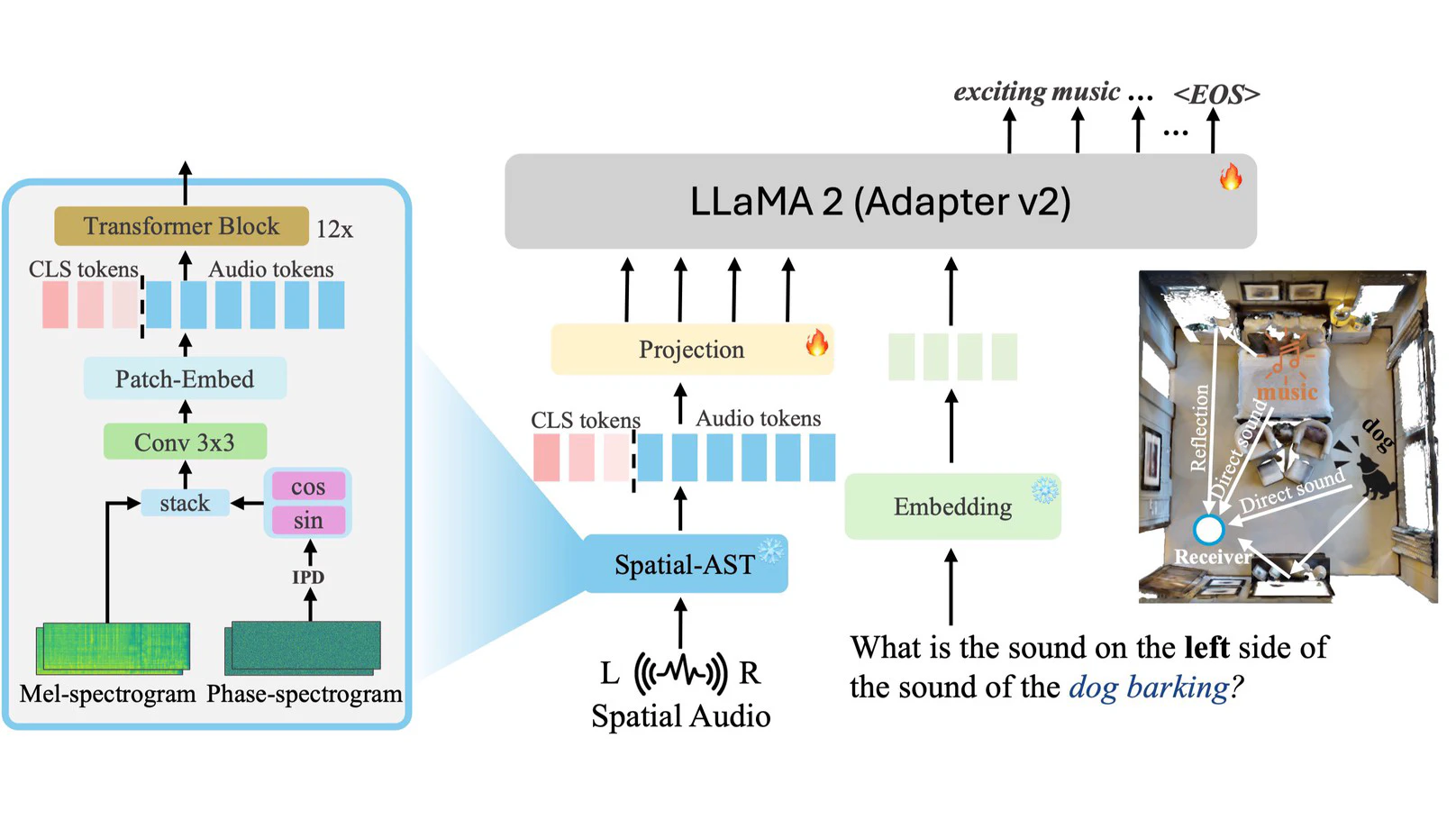
Experience
Awards & Honors
- Shanghai Outstanding Graduates, 2024
- SenseTime Scholarship for Undergraduate AI Researchers (30 winners nationwide each year), SenseTime, 2023
- Rongchang Science and Technology Innovation Scholarship (<0.1%), Shanghai Rongchang Public Welfare Foundation, 2023
- Best Student Paper Shortlist, INTERSPEECH, 2023
- Zhiyuan College Honors Scholarship (TOP 10%), 2020-2024
- Tencent Scholarship (TOP 2%), Tencent Technology (Shenzhen) Co., Ltd., 2021