CtrlSpeech: Coarse-to-Fine Control for Expressive Speech Synthesis
Abstract
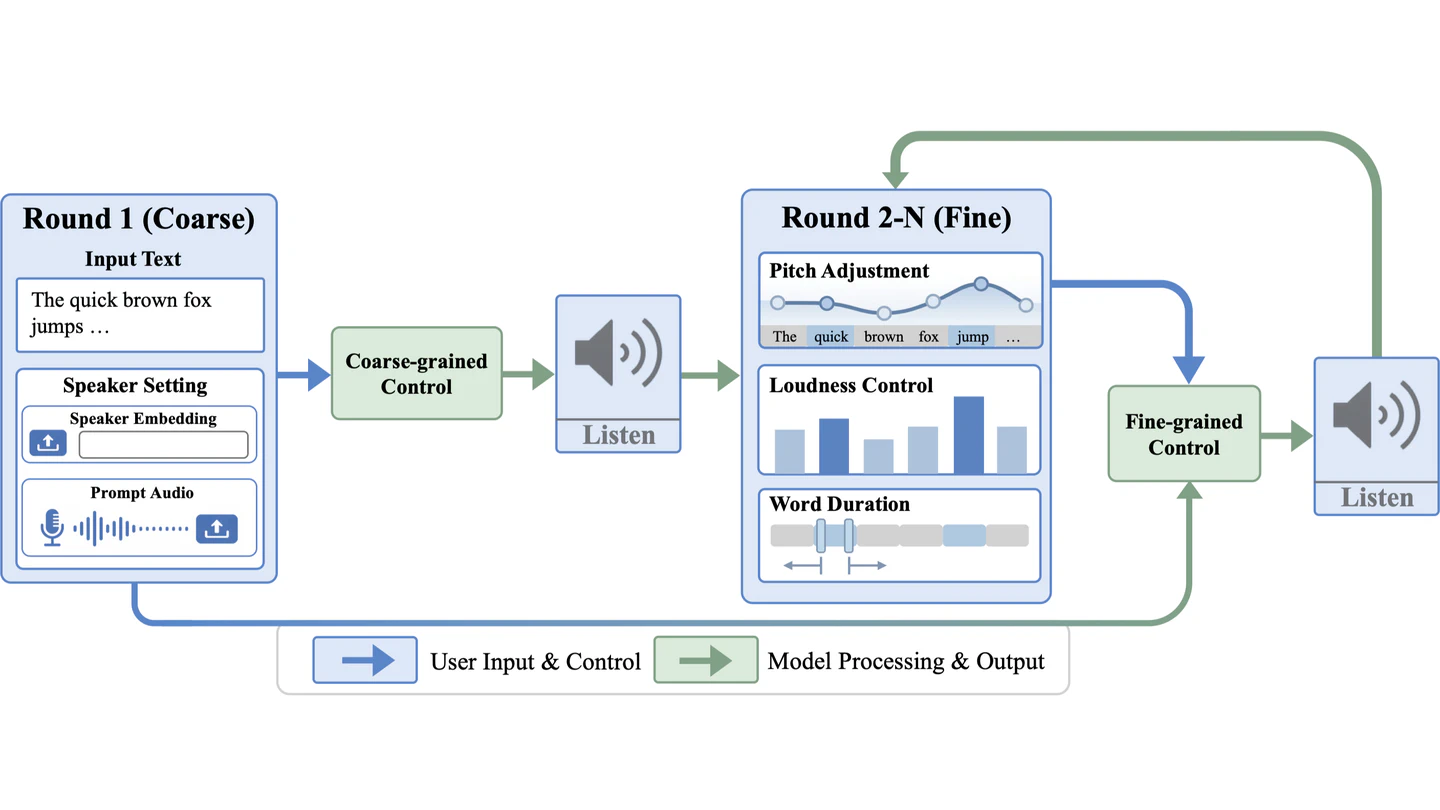
Recent Text-To-Speech (TTS) systems have achieved strong naturalness and zero-shot voice cloning performance, but fine-grained control of expressive speech at the word or phoneme level remains challenging. We propose CtrlSpeech, a controllable, expressive TTS framework with coarse-to-fine control. Built on the DiTAR architecture, CtrlSpeech combines global speaker conditioning with phone-aligned pitch, loudness, and duration signals, enabling localized prosodic control while preserving the target speaker’s timbre. This design allows users to adjust expressive attributes at a fine temporal granularity, making speech refinement more flexible and controllable. Experimental results show that CtrlSpeech achieves competitive zero-shot TTS performance and improves controllability over expressive attributes, demonstrating its effectiveness for flexible and practical expressive speech synthesis.