EXPLORING EFFECTIVE DISTILLATION OF SELF-SUPERVISED SPEECH MODELS FOR AUTOMATIC SPEECH RECOGNITION
 Distillation
Distillation
Abstract
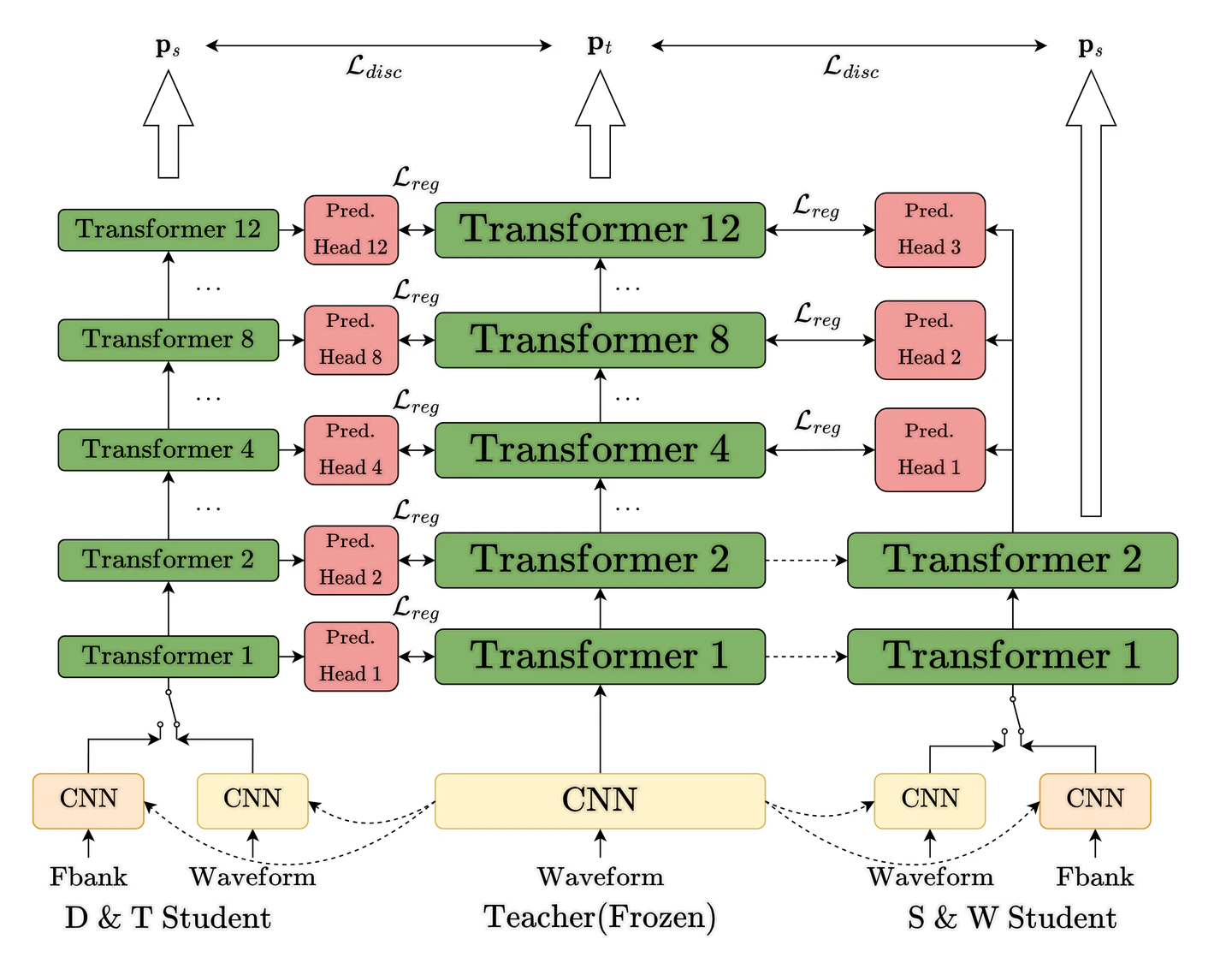
Recent years have witnessed great strides in self-supervised learning (SSL) on the speech processing. The SSL model is normally pre-trained on a great variety of unlabelled data and a large model size is preferred to increase the modeling capacity. However, this might limit its potential applications due to the expensive computation and memory costs introduced by the oversize model. Miniaturization for SSL models has become an important research direction of practical value. To this end, we explore the effective distillation of HuBERT-based SSL models for automatic speech recognition (ASR). First, in order to establish a strong baseline, a comprehensive study on different student model structures is conducted. On top of this, as a supplement to the regression loss widely adopted in previous works, a discriminative loss is introduced for HuBERT to enhance the distillation performance, especially in low-resource scenarios. In addition, we design a simple and effective algorithm to distill the front-end input from waveform to Fbank feature, resulting in 17% parameter reduction and doubling inference speed, at marginal performance degradation.