 TriBERT
TriBERT
Abstract
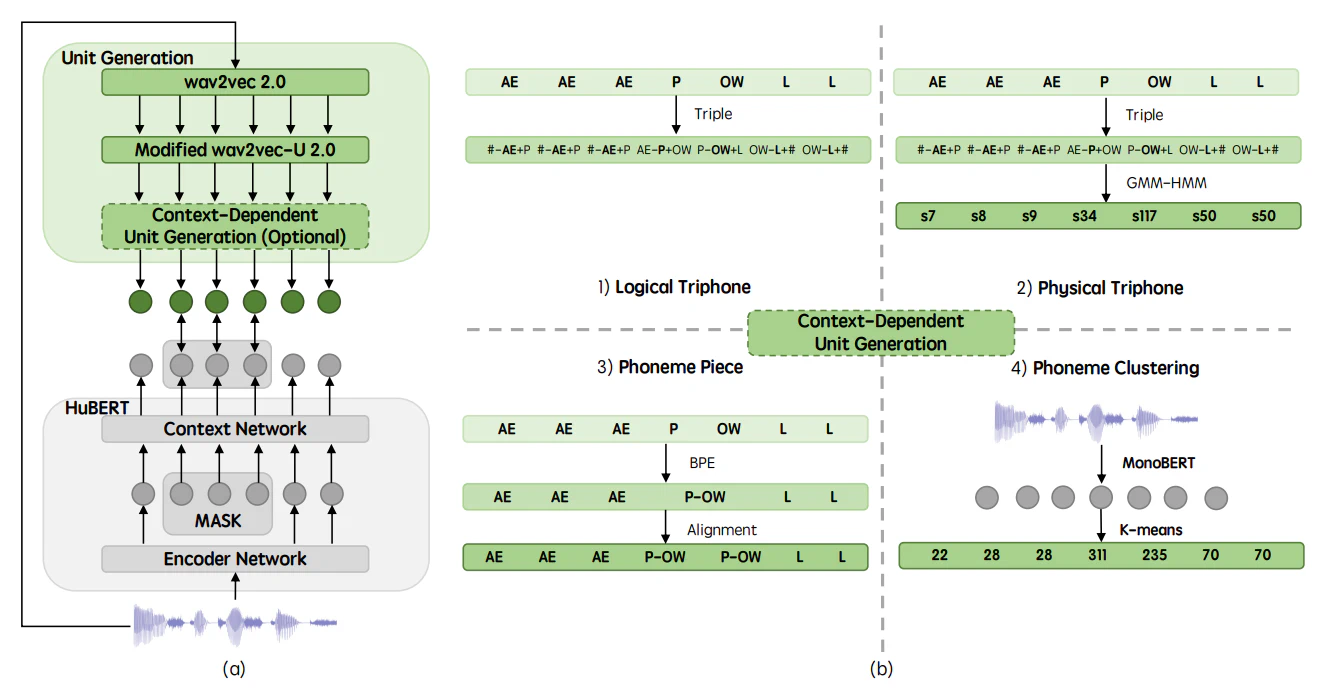
The excellent generalization ability of self-supervised learning (SSL) for speech foundation models has garnered significant attention. HuBERT is a successful example that utilizes offline clustering to convert speech features into discrete units for a masked language modeling pretext task. However, simply clustering features as targets by k-means does not fully inspire the model’s performance. In this work, we present an unsupervised method to improve SSL targets. Two models are proposed, MonoBERT and PolyBERT, which leverage contextindependent and context-dependent phoneme-based units for pre-training. Our models outperform other SSL models significantly on the LibriSpeech benchmark without the need for iterative re-clustering and re-training. Furthermore, our models equipped with context-dependent units even outperform targetimprovement models that use labeled data during pre-training. How we progressively improve the unit discovery process is demonstrated through experiments.