MT4SSL: Boosting Self-Supervised Speech Representation Learning by Integrating Multiple Targets
 MT4SSL
MT4SSL
Abstract
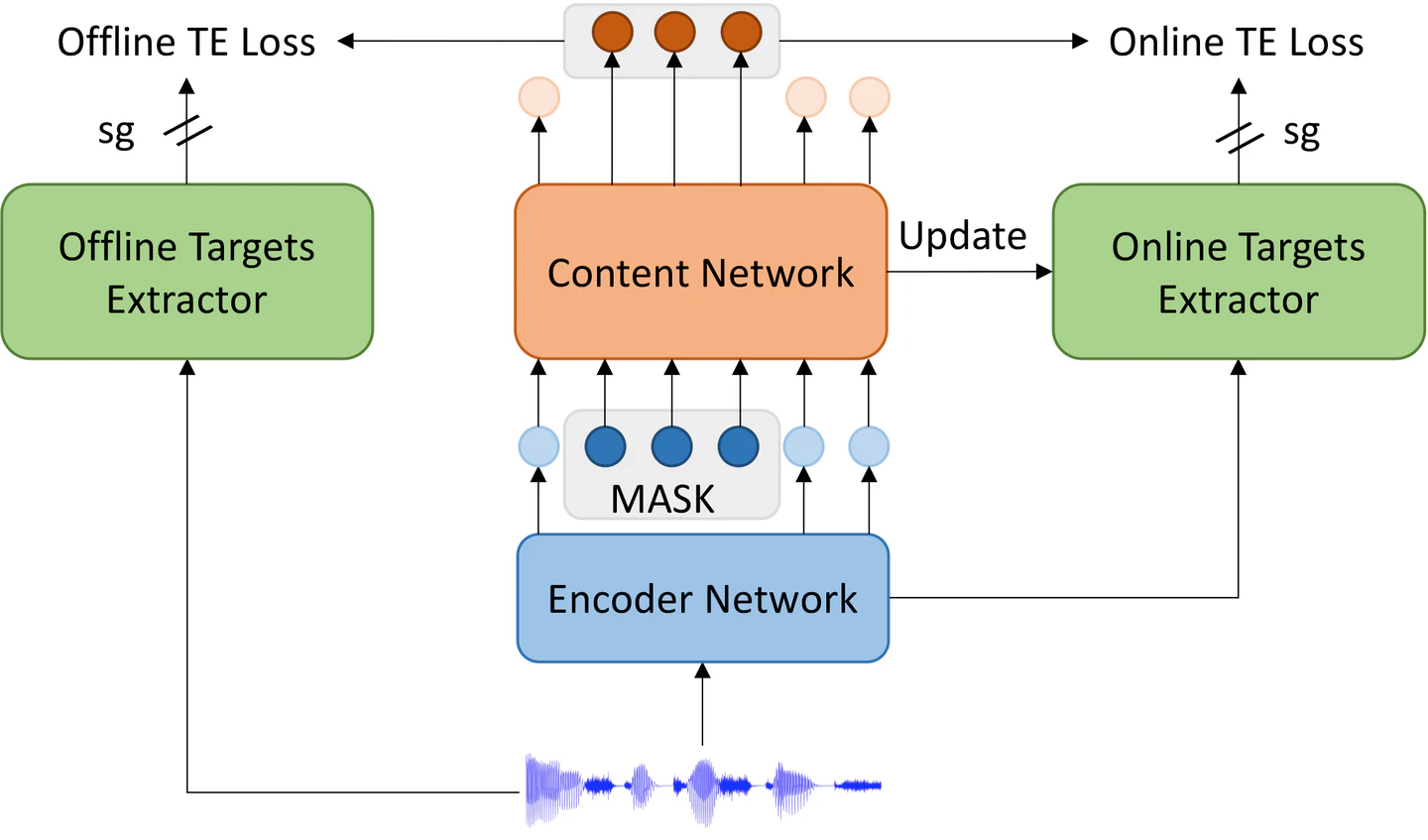
In this paper, we provide a new perspective on self-supervised speech models from how the self-training targets are obtained. We generalize the targets extractor into Offline Targets Extractor (Off-TE) and Online Targets Extractor (On-TE). Based on this, we propose a new multi-tasking learning framework for self-supervised learning, MT4SSL, which stands for Boosting Self-Supervised Speech Representation Learning by Integrating Multiple Targets. MT4SSL refers to two typical models, HuBERT and data2vec, which use the K-means algorithm as an Off-TE and a teacher network without gradients as an On-TE, respectively. Our model outperforms previous SSL methods by nontrivial margins on the LibriSpeech benchmark, and is comparable to or even better than the best-performing models with no need for that much data. Furthermore, we find that using both Off-TE and On-TE results in better convergence in the pre-training phase. With both effectiveness and efficiency, we think that doing multi-task learning on self-supervised speech models from our perspective is a promising trend.