FRONT-END ADAPTER: ADAPTING FRONT-END INPUT OF SPEECH BASED SELF-SUPERVISED LEARNING FOR SPEECH RECOGNITION
 FRONT-END ADAPTER
FRONT-END ADAPTER
Abstract
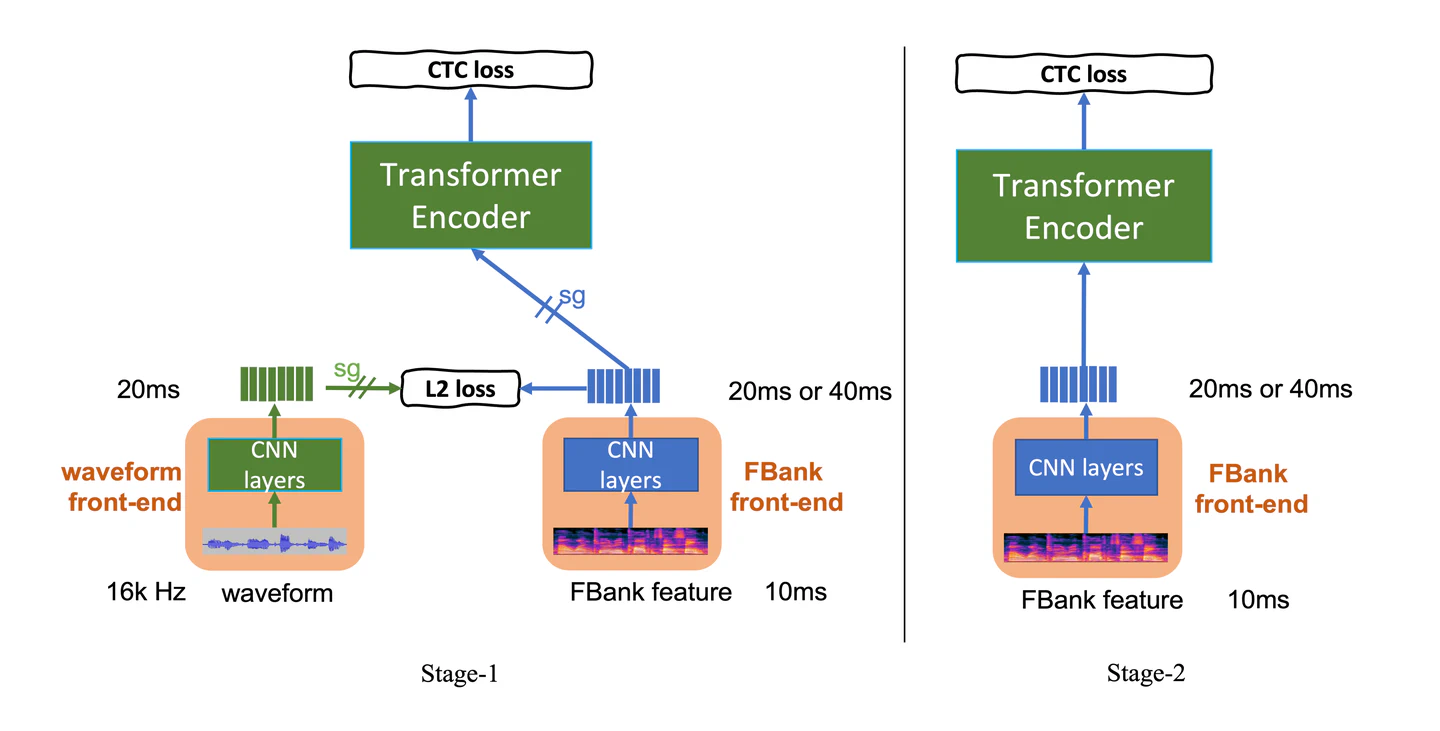
Recent years have witnessed a boom in self-supervised learning (SSL) in various areas including speech processing. Speech based SSL models present promising performance in a range of speech related tasks. However, the training of SSL models is computationally expensive and a common practice is to fine-tune a released SSL model on the specific task. It is essential to use consistent front-end input during pre-training and fine-tuning. This consistency may introduce potential issues when the optimal front-end is not the same as that used in pre-training. In this paper, we propose a simple but effective front-end adapter to address this front-end discrepancy. By minimizing the distance between the outputs of different front-ends, the filterbank feature (Fbank) can be compatible with SSL models which are pre-trained with waveform. The experiment results demonstrate the effectiveness of our proposed front-end adapter on several popular SSL models for the speech recognition task.